using quill(scala) DSL as better SQL language
Query In Scala Worksheet
add quil as dependency in sbt
libraryDependencies ++= Seq(
"org.postgresql" % "postgresql" % "42.2.8",
"io.getquill" %% "quill-jdbc" % "3.16.4-Beta28",
)
Note: I am using Scala3, for scala2, I guess the setup will be similar.
Create Scala Worksheet
create a scala worksheet with contents as below:
import io.getquill._
import com.zaxxer.hikari.{HikariConfig, HikariDataSource}
val pgDataSource = new org.postgresql.ds.PGSimpleDataSource()
pgDataSource.setUser("postgres")
pgDataSource.setPassword("123456")
pgDataSource.setDatabaseName("titan")
pgDataSource.setServerNames(Array("localhost"))
pgDataSource.setPortNumbers(Array(5432))
val config = new HikariConfig()
config.setDataSource(pgDataSource)
// SnakeCase turns firstName -> first_name
val ctx = new PostgresJdbcContext(SnakeCase, new HikariDataSource(config))
import ctx._
After set up the quill jdbc context, create the model for your database tables. As shown in https://www.lihaoyi.com/post/WorkingwithDatabasesusingScalaandQuill.html
case class City(
id: Int,
name: String,
countryCode: String,
district: String,
population: Int
)
case class Country(
code: String,
name: String,
continent: String,
region: String,
surfaceArea: Double,
indepYear: Option[Int],
population: Int,
lifeExpectancy: Option[Double],
gnp: Option[scala.math.BigDecimal],
gnpold: Option[scala.math.BigDecimal],
localName: String,
governmentForm: String,
headOfState: Option[String],
capital: Option[Int],
code2: String
)
case class CountryLanguage(
countrycode: String,
language: String,
isOfficial: Boolean,
percentage: Double
)
Run Query
print(ctx.run(query[City]))
print(ctx.run(query[Country]))
print(ctx.run(query[CountryLanguage]))
ctx.run(query[City].filter(_.name == "Singapore"))
join
ctx.run(
query[City]
.join(query[Country])
.on { case (city, country) => city.countryCode == country.code }
.filter { case (city, country) => country.continent == "Asia" }
.map { case (city, country) => city.name }
)
using for,
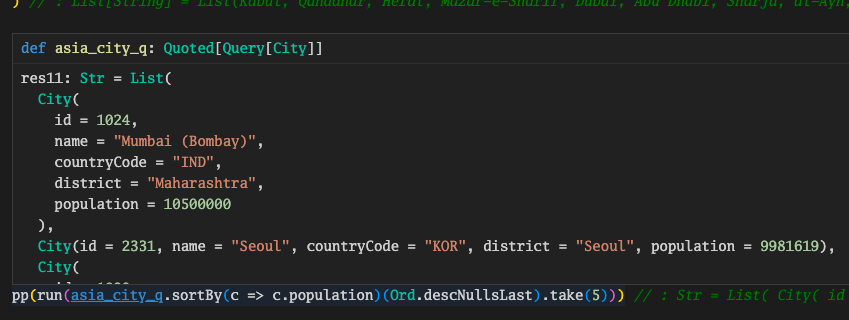
inline def asia_city_q = quote {
for {
country <- query[Country].filter(_.continent == "Asia")
city <- query[City].join(_.countryCode == country.code)
} yield city
}
# sort and limit
run(asia_city_q.sortBy(c => c.population)(Ord.descNullsLast).take(5))
It is recommended to add a ctx.close() at the end of worksheet files. Otherwise, the connection to database will be left open for each worksheet evaluation.
Extra: better display support
so far, the DSL is very easy and enjoyable to work with, but the result display in worksheet is subpar.
fortunately, we have pprint
val pp = pprint.PPrinter.BlackWhite
pp(run(asia_city_q.sortBy(c => c.population)(Ord.descNullsLast).take(5)))
hover the mouse over pp line, will display the result in a float box.
Extra: Auto Gen Model for Existing Database
//> using scala "2.13.8"
//> using lib "io.getquill::quill-codegen-jdbc:3.10.0"
//> using lib "org.postgresql:postgresql:42.2.8"
import io.getquill.codegen.jdbc.SimpleJdbcCodegen
import io.getquill.codegen.model.SnakeCaseNames
import org.postgresql.ds.PGSimpleDataSource
object GenModel extends App {
val pgDataSource = new PGSimpleDataSource()
pgDataSource.setURL("jdbc:postgresql://hostname:5432/db")
pgDataSource.setUser("titan")
pgDataSource.setPassword("123456")
val gen = new SimpleJdbcCodegen(pgDataSource, "net.bestqa") {
override def nameParser = SnakeCaseNames
}
gen.writeFiles("src/main/scala/net/bestqa")
}
It is very convienient to use scala-cli to run the script above.